
Doing research on Human Computer Interaction in Hybrid Societies requires a lot of expertise, many people, and interdisciplinary, collaborative data exchange activities. But all three aspects can only create value if they are targeted, coordinated and amplified systematically. Especially during a global pandemic, where science mainly has to happen in digital remote work environments in an effective way.

The German Research Foundation (DFG) recommends collaborative research centers (CRCs) for these activities a dedicated information infrastructure service project (INF). The main purpose of the INF project is to create and manage an appropriate, structured, sustainable research data platform to enable collaboration and data exchange among all participants and beneficiaries. This encompasses both the technical establishment of carefully selected software applications, the definition of guidelines, and even more important, the education and social interaction with all project partners in order to glue all efforts together in a single point of data access in order to achieve excellence.
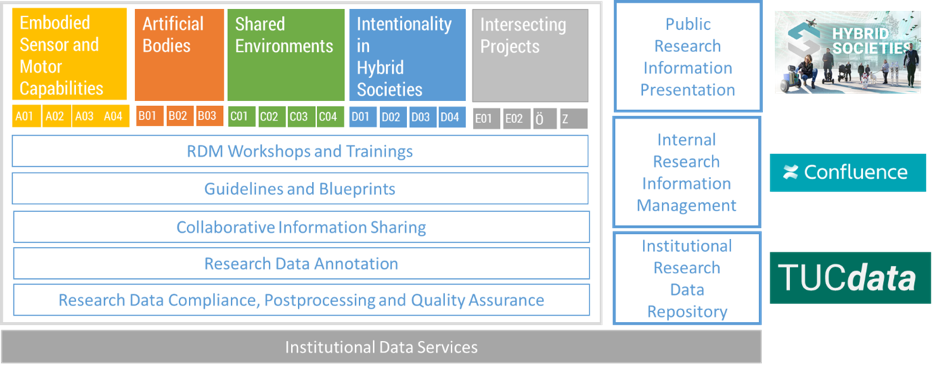
In our CRC1410 Hybrid Societies, there are currently 140 people working together in 2021, including scientific project leads, doctoral candidates and supporting staff personnel. They contribute to work activities in 21 CRC sub projects taking place in all 8 main faculties at Chemnitz University of Technology. Each of these sub projects has different requirements, organizational standards, and experience levels. Furthermore, 37 trans-sub-project cooperations were already established during the first project year. It was obvious from the very beginning, that simply exchanging emails and saving files in a shared folder would result in a chaotic and displeased situation. However, substituting all established work procedures in the variety of sub projects with a mandatory process would probably lead to a similarly negative effect.
In our CRC1410 INF team, we have therefore chosen a social, community-driven, collaborative approach that differentiates between internal research information management, research data management and public research information presentation.
Internal Research Information Management
For internal research information management, we have chosen and successfully applied for scientific purposes a self-hosted version of Atlassian Confluence as a single point of information access, available for all members of CRC1410 Hybrid Societies. The platform is administered by the CRC1410 INF team with a high emphasis on data protection and data privacy in mind. Dedicated workshops were offered in advance to train all project participants in how to use such a collaborative platform in an effective way . Within the first project year, 1.905 pages with more than 1.500 file attachments were created in a coordinated fashion, providing insights in the research progress of all sub projects, meeting activities as well as management information, resulting in 3.6 million internal page views and 48 GB data traffic so far. Internal research information management also subsumes information about recent scientific publications of all current CRC members and available shared laboratory instrumentation. Beyond that, an asynchronous knowledge exchange space is provided to collect and discuss relevant terminologies related to Hybrid Societies research. Of course, all CRC1410 members are free to decide to which extent they make use of the provided Confluence platform or whether alternative or additional established software applications are used for their internal management purposes.
Research Data Management
For the provision of research artifacts, such as generated datasets containing experimental data, we currently adopt a CKAN-based OpenData platform and establish it as an institutional research data repository at Chemnitz University of Technology (TUCdata). Members of the CRC1410 Hybrid Societies will be trained in 2021 to share their existing research data with other partners of the Collaborative Research Center according to the FAIR and CARE principles in an interdisciplinary and sustainable fashion. Our INF project is not simply seen as a service element overspanning all other sub projects, but instead a fully equal scientific project delivering highly relevant research results on publishing interdisciplinary research over Linked Data. We put high emphasis on an integrated solution within the existing university infrastructure, structured semantic metadata collection as well data quality aspects. This currently also includes the supply of a guideline with file naming conventions for storing project-related files internally. Published research data on Hybrid Societies will be available for at least 10 years and will also be announced to other research data registries, such as DFG RIsources, re3data, OpenDOAR or OpARA.
Public Research Information Management
Establishing interfaces and data exchange with other external services and applications is highly relevant for public research information presentation. The INF team works closely together with the Public Relations team (project Ö) and the management team (project Z) of the CRC1410 Hybrid Societies to automate the exchange of structured information, such as for accepted scientific publications, involved researchers, or related sub projects, without the need to enter each piece of information manually multiple times or facing inconsistent or incomplete information. This currently mainly applies for the new public Hybrid Societies project website. But interfaces are also being established to other applications such as the TUCfis Research Information Management System or the university bibliography.
The INF sub project of the CRC1410 Hybrid Societies is lead by the teams of Prof. Dr.-Ing. Martin Gaedke, responsible for research information management, and Prof. Dr. jur. Dagmar Gesmann-Nuissl, focusing on legal aspects in sharing research data. Our next steps will be the establishment of a Hybrid Societies taxonomy to interdisciplinarily describe shared research data and the automated anonymization of it. We will keep you up to date in follow-up blog articles.
André Langer (INF) and Christoph Göpfert (INF)